How I built my own Langchain from scratch in Go (Agent SDK)
April 8, 2026 • 6 min read
Go Agent SDK series - Part 1

Prerequisites: Basic understanding of APIs, JSON, and Go structs. Rest will be taken care of :)
Table of contents
Every agent framework you see is a wrapper around API calls, essentially a humongous for loop of multiple API calls and functions.
Any agent framework can be defined as an abstraction of four fundamentals:
- API structs
- Messages
- History
- Tools
While these principles have been coded and tested to death in Python's environment, I thought it would be an interesting challenge to code them in Golang and that is the reason why I started writing my own from scratch.
This lets me learn from first principles, play and tweak the API down to the smallest parameter, grow myself learning Golang the non-traditional way, and on the way I hope to make an agent framework meant to be concurrent-friendly and lightweight.
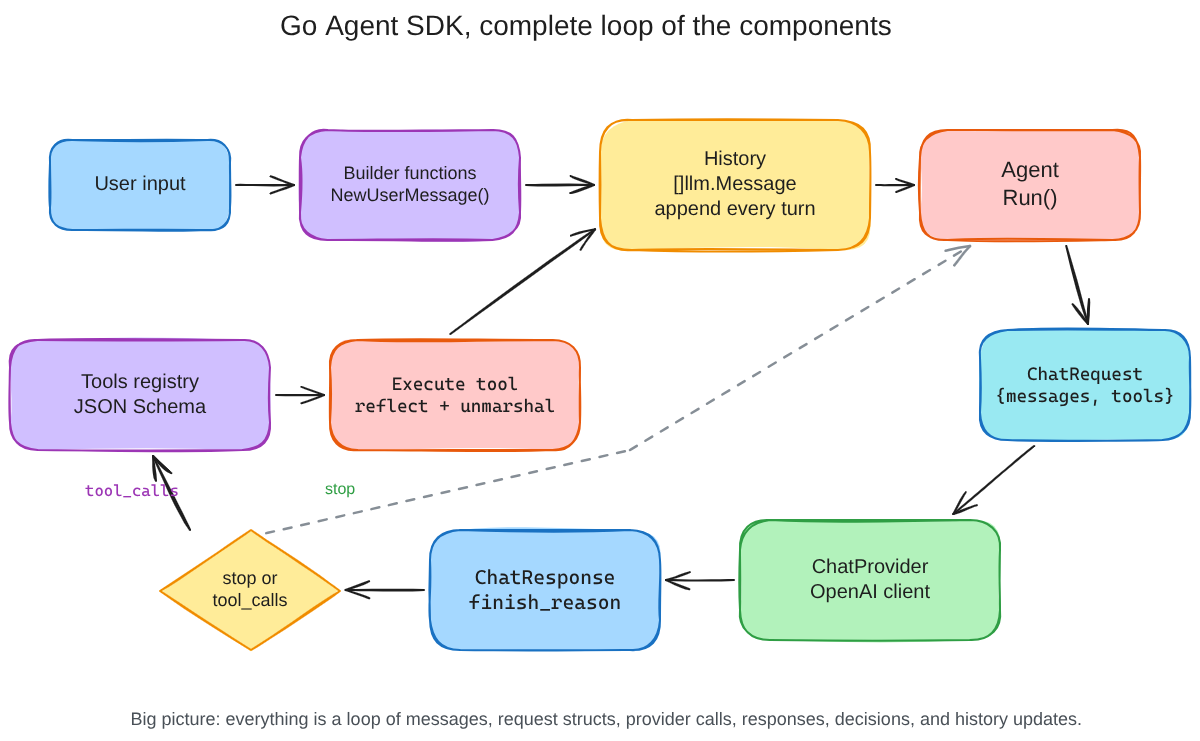
This blog will cover my learning, my thought process I had while building this and in general my building states. This first part covers the backbone, the structs that hold our data, the messaging infrastructure, and how we maintain history across turns. Tool calling deserves its own deep dive, which is what part two is about.
You can take a look at the code here - github.com/parthshr370/Go-Agent-sdk
Starting point - Defining the structs
Essentially to access any Language model we trigger an API, that API returns certain information and that information is the heart of our entire system. That heart comes to us in a pre-organised state (the API schema) which we trigger to get our response.
When building the very first version of this SDK, the first thought that struck me was handling the data structures/API schema.
The general idea is that each LLM is accessed through a very detailed API, something that can look like:
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-4",
"system_fingerprint": "fp_44709d6fcb",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"city\": \"Paris\"}"
}
}
],
"refusal": null
},
"logprobs": null,
"finish_reason": "tool_calls"
}
],
"usage": {
"prompt_tokens": 82,
"completion_tokens": 32,
"total_tokens": 114
}
}This tells us to accommodate all the parameters in the JSON response of the API into something Golang can understand. If we nail this, then our entry point becomes Go native instantly, and then building the harness that has all its incoming stream in Go native types.
While everything in Python can be written with JSON and baseclasses, Go does not have the concept of classes/Objects per se, rather they use something called structs here.
The idea is that we pre-write the expected structures of the whole API lifecycle in a data structure that Go understands. We know what to expect, pre-build the schema in advance, and then make sure all the data that we receive is recorded in these data structures and all the data structures we return is converted back to the JSON that the API understands.
In order to convert JSON to struct and struct to JSON we use something called marshalling.
Side note: if you wanna learn about how marshalling works in Go you can take a look at this blog, but to cut it short, the basic idea is to convert JSON to a format that Go can understand (unmarshalling) and then back from structs to JSON for external systems to understand (marshalling). This is the bridge that makes our structs and the API talk to each other, every request we send gets marshalled out of our structs, and every response we get back gets unmarshalled into them.
One example struct we can take a look at is:
type ChatRequest struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Temperature float64 `json:"temperature,omitempty"`
TopP float64 `json:"top_p,omitempty"`
Stream bool `json:"stream,omitempty"`
MaxTokens int `json:"max_tokens,omitempty"`
PresencePenalty float64 `json:"presence_penalty,omitempty"`
FrequencyPenalty float64 `json:"frequency_penalty,omitempty"`
Tools []Tool `json:"tools,omitempty"`
ToolChoice interface{} `json:"tool_choice,omitempty"`
}
I trimmed the full struct down a bit, you get the idea. Required fields at the top, optional ones below with omitempty, tool config at the bottom.
This schema follows OpenAI standards for now (most compatible).
Once the request structures are taken care of, we do this for all possible formats we can receive the data in (message, tool, toolcall, response) and define them in the types.go file.
The most important one of those is the Message struct, because that is what everything flows through:
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
Name string `json:"name,omitempty"`
ToolCalls []ToolCall `json:"tool_calls,omitempty"`
ToolCallID string `json:"tool_call_id,omitempty"`
}
Look at the fields here. Role and Content cover normal conversations. ToolCalls only shows up when the assistant wants to call a tool. ToolCallID only shows up when we are sending a tool result back. The struct holds every shape a message can take, and the omitempty tags make sure we only send what the API expects for that particular role.
Now we take care of the messaging architecture.
The carrier pigeons in the nest - Messaging infra
When we create such elegant structs for our agents to deal with, we create a problem for ourselves doing so. While on the surface the idea of a conversation is as simple as text in and text out, beneath the surface the API still needs to follow a strict schema.
The messages for each situation we encounter need to be in a format that the API understands. To tackle this, I created builder functions that would return me the exact schema for my particular turn of event.
Side note: builder functions are a pattern where instead of constructing a struct manually every time (and risking a wrong role or a missing field), you wrap it in a function that does it for you. Call NewUserMessage("hello") and you get a properly shaped Message back, no chance of accidentally setting the role to "usr" or forgetting the content field.
In essence our schemas need to follow a pattern which can go like:
{
"role": "user/assistant/system",
"content": "the content associated with the respective entity here"
}The idea is to give the key (the entity at the current turn) the value (can be a string or something associated with that key) it deserves in a schema, to make sure our API accepts and understands who is the one sending the message.
We can have our builder functions for user, assistant, and system messages look something like this:
func NewSystemMessage(content string) Message {
return Message{
Role: "system",
Content: content,
}
}
func NewUserMessage(content string) Message {
return Message{
Role: "user",
Content: content,
}
}
func NewAssistantMessage(content string) Message {
return Message{
Role: "assistant",
Content: content,
}
}Once the essentials are taken care of (user, assistant, and system), we have one more message type which we need to take care of, ie tool calls.
For now we can just think of tool calls as functions that your LLM API can call on your local system. Since they are really important to the overall way we design these agent SDKs, their messages need different fields than the basic ones above. We will not go deep into how tool calls get registered or executed here (that is part two), but we still need to understand how their messages are shaped because history depends on it.
When the LLM decides to call a tool, it sends a special assistant message containing the tool call details (not a content string, but a ToolCalls array). The result from executing that tool comes back as a tool message with a ToolCallID that links it back to the original call. If execution fails, we surface that error directly, failure context is more useful to the LLM than a generic success signal so it can adjust its next attempt.
func NewToolCallMessage(calls []ToolCall) Message {
return Message{
Role: "assistant",
ToolCalls: calls,
}
}
func NewToolResult(toolCallID string, name string, output string) Message {
return Message{
Role: "tool",
ToolCallID: toolCallID,
Name: name,
Content: output,
}
}
func NewToolError(toolCallID string, name string, err error) Message {
return Message{
Role: "tool",
ToolCallID: toolCallID,
Name: name,
Content: fmt.Sprintf("Error executing tool: %v. Please fix your arguments.", err),
}
}
Notice how NewToolResult and NewToolError both carry a toolCallID. That is the linkage. The API needs to know which tool result corresponds to which tool call, and that ID is the thread between them.
Now that we know how messages are built, we focus on a paradigm that is formed by collecting messages in the right order, ie the agent history.
History
While building these agent systems, one thing that is really important is the retention of information we pass on to the agent and the user at each step.
History is essentially an array of messages we created that hold the information about the user, the system, the assistant, and tool results. They tell the story of the lineage of things that have been said across the conversation.
Imagine it something like this:
[]Message{}
Turn 1: append(system message: "You are a helpful assistant")
Turn 2: append(user message: "hello how are you")
Turn 3: append(assistant message: "hello I am great how can I help you")
Turn 4: append(tool call message: get_weather with {city: "Paris"})
Turn 5: append(tool result: "Sunny, 22C")The idea is just to append to this array whenever a turn happens (agent speaks, user speaks, agent prompts a tool call, or a tool result comes back).
Conversations start by building out this array and appending till the conversation stops. Every tool call, every message gets recorded by the framework and gets sent back to the API in each turn.
And this cycle continues. The agent sends the full history array to the LLM on every single request. That is how the LLM knows what happened before, the history is the memory.
Side note: you might be wondering, who orchestrates all of this? Who takes the user message, appends it to history, sends it to the API, checks if the response is a tool call or a final answer, and loops accordingly? That is the Run() function. It is the conductor that makes structs, messages, and history work together as a single loop. We will see it in action once we have all the pieces, including tool calling, in part two.
Bookend
So far we have built the skeleton structs that map to the API, message builders that create the right schema for each turn, and a history array that records everything said. Marshalling bridges the gap between our Go types and the JSON the API speaks. Builder functions make sure every message is shaped correctly. History makes sure nothing is forgotten across turns.
But an agent that just talks in circles is not very useful. The next piece is what makes it actually do things in our systems, tool calling. How does a Go function become something the LLM knows about? How does the LLM trigger it? How do we bridge the gap between JSON arguments and actual Go code? And how does the Run() loop tie it all together? That is what part two is about.
Further reading
- Go Agent SDK - Part 2 - the next post covering tool registration, schema generation, execution, and result flow
- Go Agent SDK repo - the full codebase behind this series
- JSON, Marshals and Go - a deeper look at the marshalling that bridges Go types and JSON
- OpenAI Chat API docs - the API schema that inspired the struct design
- Go
encoding/jsondocs - the package that makes marshalling work